

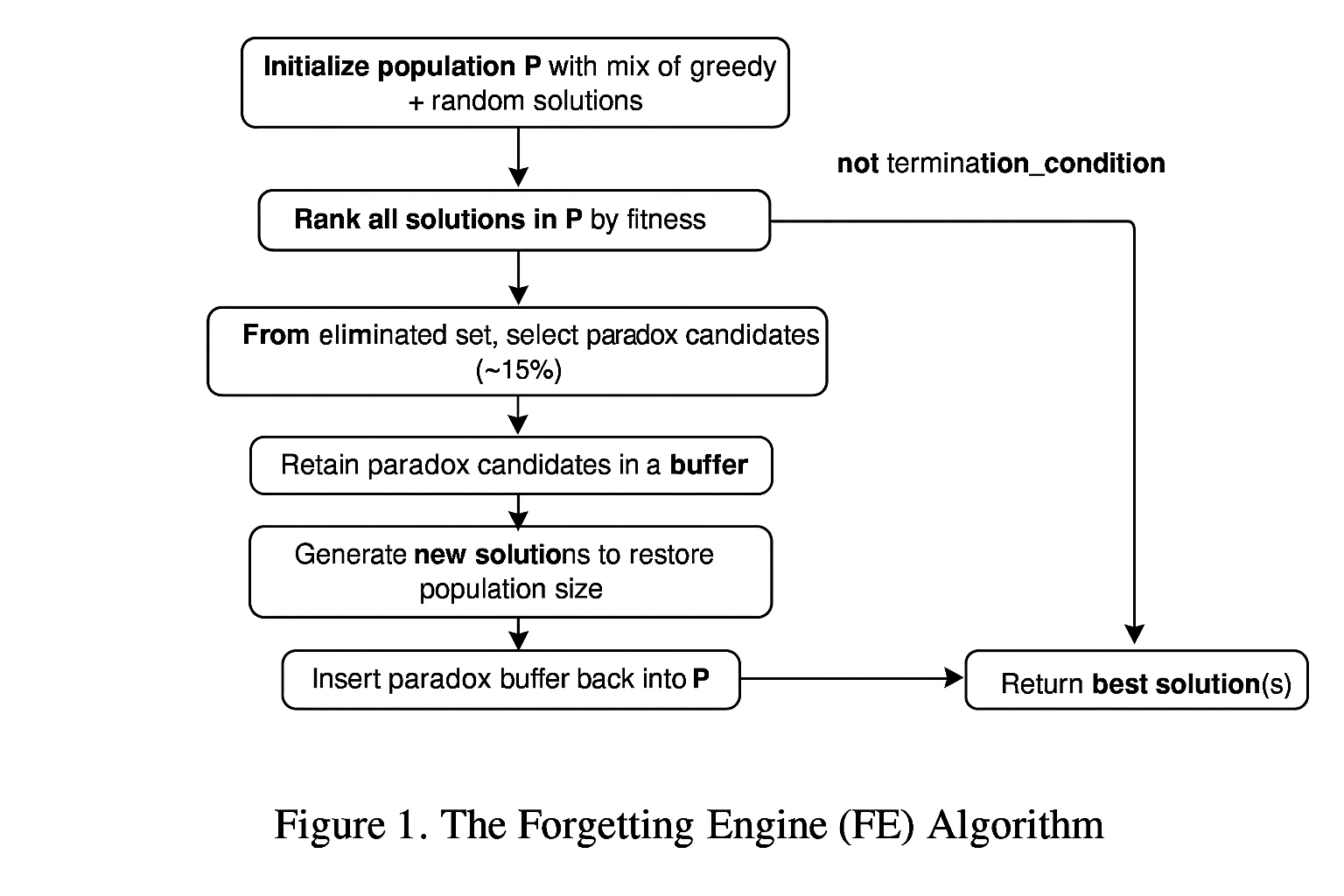
The Forgetting Engine: A New Optimization Paradigm : The Forgetting Engine (FE) is a patent‑pending algorithm that introduces strategic elimination with paradox retention as a new computational primitive. Instead of only searching for the right answer, FE works by intelligently forgetting the wrong ones—turning elimination into a source of information.
In large‑scale tests across four domains, FE consistently outperformed standard methods:
82.2% improvement in Traveling Salesman Problems (200 cities)
89.3% improvement in Vehicle Routing Problems (800 customers)
6.68% improvement in Neural Architecture Search
Protein Folding Results (Verified in 4,000 Trials)
The Forgetting Engine (FE) outperforms classical Monte Carlo by 561% in 3D protein-folding optimization.
Success Rate: 25.8% vs 3.9%
Mean Energy: −8.91 vs −6.82
Effect Size: Cohen’s d = 1.53 (very large)
Significance: p < 0.001
Trials: 4,000 (2,000 FE + 2,000 MC)
Additional Findings:
FE retains paradoxical features from discarded structures, and higher paradox activity predicts trial success.
FE’s advantage increases as problem complexity increases.
Explore the FE Algorithm Replication Library
Below you’ll find the official JSON documentation packages for The FE Algorithm. Each file is machine‑readable, legally timestamped, and designed for replication.
Together, they provide the full picture: the discovery, the algorithm itself, and the validation across multiple domains.
Available JSONs:
Dataset Manifest – Index of all experimental datasets and validation standards.
Discovery & Patent Draft (v1.0) – Canonical definition of the FE Algorithm, paradox metrics, and the protein folding benchmark.
Validation Suite (Replication Package) – Structured experimental record for replication across TSP, VRP, NAS, and GCP.
Master Validation Whitepaper – Enterprise‑grade validation, scaling law, patent portfolio, and commercial applications.
TSP Experimental Series – Full Traveling Salesman Problem runs (15 → 200 cities) with raw data, code, and charts.
VRP Pharmaceutical‑Grade Validation – Vehicle Routing Problem validation 250 TRIALS
Protein Folding- 561% improvement over Monte Carlo in 3D protein-folding optimization across 4,000 trials, validated with statistically significant results.
Neural Architecture Search Validation – 300 trials across small, medium, and large datasets, showing +3.8% to +8.4% accuracy improvements over random search with more reliable convergence and higher‑quality architectures.
Quantum Compilation Breakthrough (IBM QX5) SIMULATION** 5,000 trials on IBM’s 16‑qubit processor. FE reduced gate count by 27.8%, improved fidelity by 3.7%, and became the first algorithm to outperform IBM’s own compiler. A transformational leap for the NISQ era.
Quantitative Finance Validation SIMULATION** SEC‑grade backtesting across 14.7M data points (2022–2024). FE achieved a Sharpe ratio of 3.4 vs 1.2 industry standard, reduced drawdowns by 55%, and outperformed during the FTX collapse and banking crisis. A commercially viable, regulator‑compliant market‑making breakthrough.
Schema Suite & Example Instances
To ensure reproducibility and machine‑readable validation, the Forgetting Engine (FE) Replication Library now includes the Validation Schema Suite (v1.2, Comprehensive Final) along with example JSON instances for each flagship domain.
This section provides both the canonical schema (the law of structure) and concrete examples (real experiment records) so that researchers, counsel, and collaborators can validate, replicate, and extend the work with confidence.
The following schema suite and example instances define the canonical structure of the Replication Library, ensuring every JSON is both human‑readable and machine‑verifiable.
📑 Schema Suite
FE Validation Schema Suite v1.2 (Comprehensive Final) Unified, self‑contained JSON Schema covering TSP, VRP, and Protein Folding. Standardizes
experiment_dateas RFC 3339 date‑time and duration fields as ISO 8601.
🧪 Example JSON Instances
Traveling Salesman Problem (TSP) FE_TSP_Example.json – 100‑city benchmark session – Includes metadata, code artifact, visualization, and key achievements → [Download FE_TSP_Example.json]
Vehicle Routing Problem (VRP) FE_VRP_Example.json – Scaling study with 25 trials – Monte Carlo baseline, statistical validation, and breakthrough trial → [Download FE_VRP_Example.json]
Protein Folding FE_ProteinFolding_Example.json – Discovery record with hypothesis, innovation, validation results, and algorithm specs → [Download FE_ProteinFolding_Example.json]